Einführung
Bei der Messung physikalischer Größen treten immer Fehler auf. Eine genaue, absolut präzise Messung ist nur beim Abzählen von Datenwerten möglich (und da auch nicht immer).
|
Eine physikalische Messung ohne Genauigkeitsangabe ist wertlos. |
Grundsätzlich müssen in jedem Praktikumsbericht neben den Resultaten auch Angaben zu den Fehlern vorhanden sein.
Man unterscheidet drei Fehlerarten: grobe Fehler, systematische Fehler und statistische Fehler. Grobe Fehler entstehen, wenn die Experimentatoren ihr Handwerk nicht verstehen (Experimentelle Physik ist in erster Linie Handwerk). Grobe Fehler lassen sich durch Literaturstudium, Kontrollmessungen und durch Abschätzungen vor dem Experiment über die zu erwartenden Größen vermeiden. Systematische Fehler treten bei jeder Durchführung eines Versuches in der gleichen Art und Weise auf. Statistische Fehler sind zufällig. Ihr Auftreten liegt in der Natur des Messprozesses und kann nur durch Wiederholung der Messungen minimiert werden.
Dieser kleine Text will Ihnen eine Zusammenfassung der für die Fehlerrechnung und Fehlerbehandlung benötigten Methoden geben.
Systematische Fehler
Systematische Fehler sind durch die Unvollkommenheit der Messgeräte sowie durch nicht steuerbare Äußere Einflüsse bestimmt. Systematische Fehler können in vielen Fällen durch ergänzende Messungen korrigiert werden (zum Beispiel die Totzeitkorrektur bei Zählrohren). Systematische Fehler können durch eine eingehende Analyse der verwendeten Messgeräte und der Messverfahren erkannt werden. Typische systematische Fehler sind:
Umwelteinflüsse
Wenn die Umwelteinflüsse nicht überwacht werden, können meistens nur qualitative Ergebnisse erwartet werden.
Eine weitere Kategorie systematischer Fehler ist die Rückwirkung des Messgerätes auf das gemessene System.
Eine weitere Quelle systematischer Fehler sind unvollkommene Messgeräte.
Messungen sind sehr viel präziser, wenn nicht ein Wert gemessen wird, sondern der Messwert mit einer Referenz (eventuell abgleichbar) verglichen wird. Hat man eine gute Theorie des Messgerätes und des Messprozesses zur Hand, können diese systematischen Fehler herausgerechnet werden.
|
Eine weitere, nicht zu unterschätzende Quelle systematischer Fehler sind die Experimentatoren. Dazu gehört insbesondere "Bias", mangelnde Objektivität. Die meisten falschen Messresultate sind dadurch zustande gekommen, dass der Experimentator das Resultat aus unzureichenden Daten herausgelesen hat, das er haben wollte. |
Systematische Fehler können entdeckt werden, indem
|
Vor einem Experiment müssen die folgenden Fragen geklärt werden:
|
Statistische Fehler
Die Forderung nach Reproduzierbarkeit ist nie streng erfüllt. Auch wenn systematische Fehler ausgeschlossen werden können oder wenn sie bekannt sind, verbleiben zufällige, statistische Fehler. Diese haben ihre Ursache zum Beispiel in
Die statistischen Fehler unterliegen, wie ihr Name sagt, den Gesetzen der Stochastik. Im folgenden wollen wir diese Fehler näher untersuchen.
Statistische Fehler
Wenn eine Messung nur einmal durchgeführt wird, so kann man über die Zuverlässigkeit keine Angaben machen. Es ist deshalb unumgänglich, Messungen zu wiederholen.
Stichproben
Die erhaltenen Messresultate sind eine Stichprobe aus der Menge aller möglichen Messresultate. Jede Stichprobe hat eine gewisse, noch zu berechnende Wahrscheinlichkeit, dass sie die Grundgesamtheit repräsentiert. Stichproben werden üblicherweise als Histogramme dargestellt. Die gemessenen Daten x werden in Klassen mit
(xi – Dxi) < x <xi
eingeteilt.
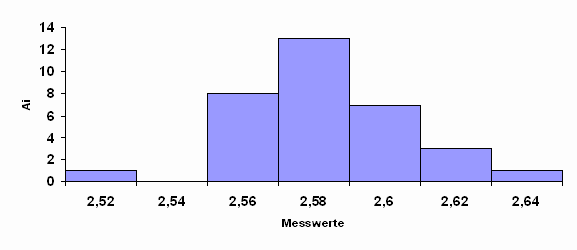
Abbildung 1 Histogramm von Messwerten.
Aus diesem Histogramm kann man den Mittelwert
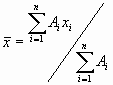
berechnen. Hier sind die Ai die Häufigkeiten der in eine bestimmte Klasse fallenden Messwerte. In unserem Falle ist dies 2,583030303. Man kann diese Gleichung umschreiben, indem man die relativen Häufigkeiten
![]()
verwendet. Der Mittelwert ist dann
![]()
Der so gefundene Mittelwert ist im allgemeinen nicht mit dem wahren Wert der Messgrösse identisch.
Wenn wir die Klassenbreite verringern und gleichzeitig die Anzahl Messpunkte erhöhen, so erhält man die differentielle Verteilungsfunktion f(x) der zugrunde liegenden Gesamtheit. Diese Funktion f(x) ist normiert, da wir die relativen Häufigkeiten zu ihrer Ableitung verwendet hatten.
![]()
Wir müssen unterscheiden zwischen den aus den experimentellen Daten empirisch gefundenen Verteilungsfunktionen und den durch theoretische Modelle berechneten Verteilungen. Eine wichtige Aufgabe einer Datenanalyse kann sein, zu zeigen, dass eine empirische Verteilungsfunktion mit einer theoretisch gefundenen verträglich ist.
Varianzen und Standardabweichungen
Eine Verteilungsfunktion ist nicht nur durch ihren Mittelwert, sondern auch durch die Lage- und Dispersionsgrössen gegeben. Wir haben gesehen, dass der arithmetische Mittelwerte(oben) eine solche Größe ist. Die Lagegrößen müssen die folgenden Postulate erfüllen:
Als Lagegrößen kommen in Frage:
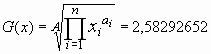
Der Median ist besonders dann zu verwenden, wenn die Stichprobe eine große Streuung aufweist. Wenn aus anderen Daten bekannt ist, dass nicht alle Messwerte die gleiche Güte haben, kann man die Ai auch als Gewicht benutzen. Hier hatten wir die Anzahl Messwerte pro Klasse als Güte des Messwertes genommen.
Es ist einsichtig, dass man zusätzlich versucht, die Breite einer Verteilung zu charakterisieren. Diese Größen heißen Dispersionsgrössen. Man verwendet:
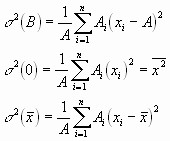
also![]() .
.
Da dies alles positiv definite Größen sind, ist die Varianz minimal, wenn sie bezüglich des arithmetischen Mittelwertes ![]() berechnet wird.
berechnet wird.
Wenn wir eine kontinuierliche Verteilung haben und p(x) die Gewichtsfunktion ist, gilt:
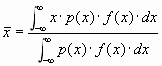
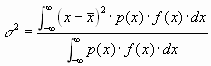
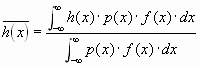
Shepard gibt an, dass ein besserer Wert für die Varianz erhalten wird bei in Klassen eingeteilten Messgrössen, wenn man die folgende Formel verwendet.
![]()
wobei h die Klassenbreite ist. In unserem Falle wäre ![]() .
.
Mittlerer Fehler und Varianz
Da der Mittelwert der Grundgesamtheit, µ, im allgemeinen nicht bekannt ist, wird die berechnete Varianz nicht die Varianz der Grundgesamtheit sein. Wir versuchen nun den besten Schätzwert für die Varianz zu berechnen. Nehmen wir an, wir würden µ kennen. Dann gilt
![]()
Im folgenden setzen wir alle Ai=1 und µ=0. Dann ist A=n. Durch ausmultiplizieren erhalten wir
![]()
mit ![]() erhält man
erhält man
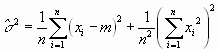
Mit
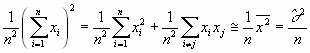
wird
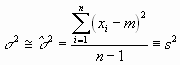
Die Größe s ist der mittlere Fehler einer Einzelmessung. Der Übergang von n nach n-1 ist zu Verstehen als der Verlust eines Freiheitsgrades. Da wir den Mittelwert der Grundgesamtheit µ nicht kennen, muss die Stichprobe zur Bestimmung von m herhalten. Dies ergibt eine neue Beziehung zwischen den Datensätzen, reduziert also die Anzahl Freiheitsgrade.
Mittlerer Fehler des Mittelwertes
Bei verschiedenen Stichproben schwanken der Mittelwert und die Varianz. Wenn wir für die Berechnung des Mittelwertes die Schreibweise
![]()
verwenden, und für den Erwartungswert
![]()
verwenden, dann gilt bei gleicher Grundgesamtheit für alle xi, dass sie den Erwartungswert ![]() und
und ![]() ist. Wenn wir den Mittelwert der Messwerte, m einsetzen, erhalten wir auch
ist. Wenn wir den Mittelwert der Messwerte, m einsetzen, erhalten wir auch ![]() . Für die Varianz gilt auch
. Für die Varianz gilt auch
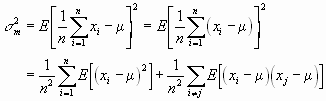
Wenn die Messdaten statistisch unabhängig sind, so ist der zweite Term=0 und wir erhalten
![]()
der mittlere Fehler sm des Mittelwertes ist also um den Faktor ![]() kleiner als der mittlere Fehler der Einzelmessung
kleiner als der mittlere Fehler der Einzelmessung
![]()
Daraus lernt man, dass, um ein Resultat doppelt so genau zu erhalten, viermal mehr Messungen durchgeführt werden müssen.
Momente der Verteilung
Das k-te Moment einer Verteilung ist definiert durch den Erwartungswert
![]()
Wenn wir B=0 setzen, so erhalten wir
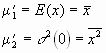
Bei den höheren Momenten benutzt man eine Normierung, damit diese dimensionslos werden.
Gebräuchlich außer dem Mittelwert und der Varianz sind:
Verteilungen
Es gibt einige Modellverteilungen, die in der Physik sehr gebräuchlich sind. Dies sind die Binominalverteilung, die bei Würfelexperimenten oder würfelartigen Experimenten zugrunde liegt, die Poisson-Verteilung und, im Grenzfall sehr großer Grundgesamtheiten, die Normalverteilung.
Binominalverteilung
Die Binominalverteilung beschreibt Experimente, bei denen in jedem einzelnen Experiment mit der Wahrscheinlichkeit p ein Ereignis eintritt und mit der Wahrscheinlichkeit q=1-p ein zweites Ereignis eintritt (oder das erste nicht eintritt). Ein Würfelspiel genügt, zum Beispiel, diesen Gesetzen. Die Wahrscheinlichkeit, dass k-mal das erste und n-k mal das zweite Ereignis eintritt ist
![]()
Wenn die Reihenfolge dieser Ereignisse irrelevant ist, dann hat man die Binominalverteilung
![]()
Die Verteilung ist normiert, da gilt
![]()
Der Mittelwert ist
![]()
Die Varianz schließlich berechnet sich zu
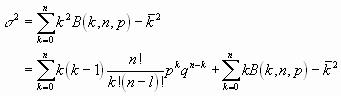
und
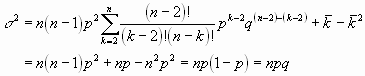
Die weiteren Momente sind (ohne Rechnung)
![]()
und
![]()
Für die Binominalverteilung existiert eine Rekursionsformel:
![]()
Zum Abschluss noch eine kurze Bemerkung: jede, auch asymmetrische Binominalverteilung geht für festes p bei großen n in die Normalverteilung über.
Normalverteilung
Die Normalverteilung kann als Grenzfall der Binominalverteilung angesehen werden, wenn die Anzahl Versuche gegen unendlich geht und p=q=0,5 ist. Die Wahrscheinlichkeit für das Auftreten einer Abweichung ist
![]()
wobei k negative und 2N-k positive Abweichungen auftreten. Wir können die Binominalverteilung verwenden:
![]()
Wir berechnen den Mittelwert. Mit ![]() wird
wird
![]()
Die Varianz wird dann
![]()
Für große N ist es sinnvoll, die Verteilung auf die Varianz 1 zu standardisieren
![]()
Diese standardisierte Variable tk hat den Mittelwert 0 und die Varianz 1. Verwenden nun Histogramme, und skalieren die Achse mit ![]() . Wir erhalten
. Wir erhalten
![]()
Mit der Stirlingschen Formel
![]()
wird
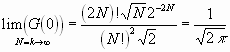
Mit Hilfe der Rekursionsformel kann gezeigt werden, dass
![]()
Für p=q=1/2 wird
![]()
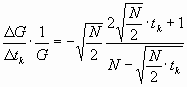
Für N® ¥ ergibt sich
![]()
Daraus folgt
![]()
Mit einer Normierung erhält man die standardisierte Gaußverteilung
![]()
oder die allgemeine Gaußverteilung
![]()
Die Gaußverteilung ist symmetrisch bezüglich des Mittelwertes µ, also sind alle ungradzahligen Momente 0. Die gradzahligen Momente haben den Wert
![]()
Damit wird zum Beispiel die Überhöhung g4=3.
Viele Experimente ergeben eine gaußförmige Verteilung der Messwerte um einen Mittelwert.
Zur Abschätzung von Fehlergrenzen kann das Integral der Gaußverteilung, die Fehlerfunktion verwendet werden.
![]()
Für den speziellen Wert ![]() wird erf(1)=0,683. Das heißt: bei normalverteilten statistischen Abweichungen ist die Wahrscheinlichkeit = 68,3 %, dass eine Messung einen Fehler innerhalb
wird erf(1)=0,683. Das heißt: bei normalverteilten statistischen Abweichungen ist die Wahrscheinlichkeit = 68,3 %, dass eine Messung einen Fehler innerhalb ![]() liefert.
liefert.
Poisson-Verteilung
Bei radioaktiven Atomen ist die Anzahl in einer bestimmten Zeit zerfallender Kerne proportional zur Gesamtzahl der Kerne. Es gilt also
![]()
Daraus folgt das Zerfallsgesetz
![]()
Anstelle der Zerfallskonstante wird meistens die Halbwertszeit T½ = ln 2 / l angegeben. Unter den folgenden Annahmen kann man die dazugehörige Verteilungsfunktion ableiten.
Viele Stöße ergeben nun eine Folge von Stoßzeiten (k1,k2,k3...). Wir berechnen nun den Erwartungswert E(k)=µ. Mit der Zerfallswahrscheinlichkeit p (proportional zu l und Dt) wird
![]()
Die Wahrscheinlichkeit für eine Zahl k von Ereignissen im Messintervall Dt kann aus der Binominalverteilung durch einen Grenzübergang nach unendlich (n® ¥ , p® 0, q® 1, np=µ=const) berechnet werden. Wir verwenden die Rekursionsformel für die Binominalverteilung
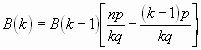
Daraus entsteht die Rekursionsformel für die Poisson-Verteilung
![]()
Mit der Normierungsbedingung ![]() bekommt man
bekommt man
![]()
Und daraus die Poisson-Verteilung
![]()
Die Poisson-Verteilung hat die folgenden Eigenschaften (erhalten aus dem Vergleich mit der Binominalverteilung):
Die Poisson-Verteilung findet man immer dann, wenn ein sehr unwahrscheinliches Ereignis bei einer großen Zahl Versuchen betrachtet wird. Neben Atomkernen sind auch die Ankunftszeiten von Photonen und Elektronen bei sehr geringem Fluss Poisson-verteilt.
Lorentz-Verteilung
Die Lorentz-Verteilung tritt in optischen Spektren auf. Sie ist da die universelle Verteilungsfunktion. Sie wird in allgemeiner Form so geschrieben:
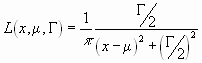
Die Lorentz-Verteilung besitzt die folgenden Eigenschaften:
Statistische Tests
Die in physikalischen Experimenten erhaltenen Daten stellen Stichproben aus einer Grundgesamtheit dar. Wir müssen nun die folgenden Fragen lösen:
Ein einfacher Test kann anhand der Standardabweichungen durchgeführt werden. So soll untersucht werden, ob bei einer Gesamtwurfzahl von 315672 die Zahl von 106602 Würfen der zahlen 5 oder 6 zur Annahme eines Homogenen Würfels (p=1/3) passt. Im Versuch ist die relative Häufigkeit 0,3377=106602/315672. Weiter ist die Standardabweichung des Mittelwertes
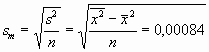
Man erwartet für einen homogenen Würfel µ=105224 mit
![]()
Die beobachtete Abweichung ist jedoch 1378, also 5,2 mal größer als s. Dieser einfache Test kann gut zu einer ersten Abschätzung der Güte einer Messung dienen.
Ein weiterer einfacher Test benutzt den Vergleich der höheren Momente. Für diesen Dispersionsindex gilt

t-Test
Der t-Test gibt eine Angabe über die Konsistenz zweier Mittelwerte. Er erlaubt eine Aussage, ob eine eigene Messung mit der eines andern (aber auch eine frühere eigene Messung) konsistent ist. Damit kann getestet werden, ob eine Apparatur sich mit der Zeit verändert.
Man könnte zur Annahme gelangen, dass wenn zwei Mittelwerte ![]() und
und ![]() sich um weniger als eine Standardabweichung unterscheiden, dass sie dann zu einer identischen Grundgesamtheit gehören. Diese Beurteilung ist willkürlich.
sich um weniger als eine Standardabweichung unterscheiden, dass sie dann zu einer identischen Grundgesamtheit gehören. Diese Beurteilung ist willkürlich.
Besser ist es, den erwarteten Fehler der Differenz ![]() zu berechnen. Mit Hilfe des Fehlerfortpflanzungsgesetzes ergibt sich
zu berechnen. Mit Hilfe des Fehlerfortpflanzungsgesetzes ergibt sich
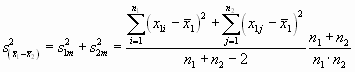
dabei sind ![]() und
und ![]() die Mittelwerte zweier Messreihen, n1 und n2 die Anzahl Messungen mit den Fehlern s1 und s2. Für
die Mittelwerte zweier Messreihen, n1 und n2 die Anzahl Messungen mit den Fehlern s1 und s2. Für ![]() setzt man am besten
setzt man am besten ![]() ein, wobei die Varianz durch das Zusammenlegen aller Messreihen berechnet wurde.
ein, wobei die Varianz durch das Zusammenlegen aller Messreihen berechnet wurde.
Für die t-Verteilung und den t-Test betrachtet man normalverteilte Zufallsvariablen y. Sind solche nicht vorhanden, dann muss mit Mittelwerten von Stichproben gerechnet werden. Wir berechnen den Mittelwert my aus der Stichprobe y und die Standardabweichung sy, die auf n Freiheitsgeraden beruht. Die t-Grösse ist dann
![]() .
.
Sie gehorcht der Studentschen t-Verteilungsfunktion
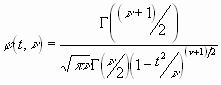
Diese Verteilungsfunktion besitzt die Kenngrössen
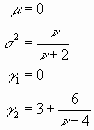
Für nÞ ¥ geht die Verteilung in die Normalverteilung über. Die Integrale Verteilungsfunktion
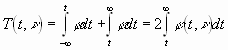
ist die Wahrscheinlichkeit, dass bei Abwesenheit systematischer Fehler t-Werte auftreten, die außerhalb des Konfidenzbereiches ± t liegen. Diese Funktion findet man in Tabellen. Für sehr umfangreiche Stichproben geht die t-Verteilung in die Normalverteilung über.
Für die (0,1) [Mittelwert 0, Varianz 1] verteilte Testgröße bekommt man
![]()
Wenn der Test erfüllt ist, dann sind die beiden Stichproben aus der gleichen Grundgesamtheit.
|
Zwei Mittelwerte mit n1=9 und n2=7 ergeben einen t-Wert von 1,74 Man findet (Die entsprechende Excel Funktion =TVERT(1,74;14;2) liefert 0,103784377) Die Interpretation sagt nun, dass
Üblicherweise verwendet man Vertrauensgrenzen (Signifikanz-Grenzen) von 5% und 1%. Nur wenn der t-Test eine Wahrscheinlichkeit kleiner als diese Werte ergibt, nimmt man eine Abweichung an. Größere Signifikanz-Grenzen (z.B. 40%) bedeuten, dass man sehr oft die Hypothese der Gleichheit verwerfen muss, obwohl sie stimmt. Mit sehr kleinen Signifikanz-Grenzen läuft man Gefahr, Gleichheit anzunehmen, obwohl sie nicht da ist. |
F-Test
Der F-Test ist ein zum t-Test analoger Test, der die Konsistenz von Varianzen prüft.
![]()
Die Verteilungsfunktion enthält die beiden Freiheitsgrade ![]() und
und ![]() . In Tabellen werden für 5% und 1% Signifikanz-Grenzen Werte angegeben.
. In Tabellen werden für 5% und 1% Signifikanz-Grenzen Werte angegeben.
Chi-Quadrat-Test
Beim c 2-Test liefert ein allgemeines Kriterium für die Übereinstimmung der Grundgesamtheit mit der Stichprobe. Der c 2-Test taugt für jede Verteilungsfunktion, ist also modellfrei. Das Vorgehen ist folgendermaßen:
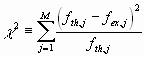
Die Verteilungsfunktion lautet:
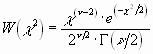
Die kennzeichnenden Größen sind:
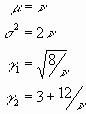
Die c 2-Verteilungsfunktion ist verwandt mit der Poisson-Verteilung: sie geht für große n in die Normalverteilung über. Wir rechnen nun die Wahrscheinlichkeit für den c 2-Wert aus der Probe aus. Der Test, ob die Stichprobe zur hypothetischen Grundgesamteit passt, gilt als bestanden, wenn die Wahrscheinlichkeit >5% ist.
Für die Anzahl Freiheitsgrade gilt:
![]()
Solche Beschränkungen sind die Normierung von fth und die Mittelwertbildung.
Für den c 2-Test ergibt sich demnach
Wenn ich bei einer Stichprobe mit 8 Messwerten ausrechne, dass der Mittelwert ![]() und die Standardabweichung
und die Standardabweichung ![]() , so wäre eine Resultatangabe von
, so wäre eine Resultatangabe von
![]()
vollkommen unsinnig. Ist der Fehler nämlich normalverteilt, so erhält man für ![]() , also sind 4 Stellen für den Mittelwert und 2 für die Abweichung angebracht:
, also sind 4 Stellen für den Mittelwert und 2 für die Abweichung angebracht:
![]()
Fehlerfortpflanzung
Im allgemeinen besteht ein Resultat eines physikalischen Experimentes nicht aus einer einzelnen Messgrösse. Wir können also die oben abgeleiteten Verfahren nicht unbesehen auf beliebige experimentelle Resultate ausdehnen. Wie wirken sich also die Einzelfehler auf die Gesamtheit aus?
Als Beispiel soll die Bestimmung einer Gitterkonstanten a nach der Debye-Scherrer-Methode besprochen werden. Röntgenstrahlen mit der Wellenklänge l fallen auf eine größere Anzahl kleiner Kristallite mit den Miller’schen Indizes h,k,l. Für den Glanzwinkel gilt:
![]()
oder
![]()
Es treten dabei die folgenden Fehler auf:
(a), (b) und (c) sind systematische Fehler. Bei (b) und (c) lassen sich Vorzeichen und Größe des Fehlers bestimmen. Bei (a) ist der Fehler für unsere Messung ein systematischer, beruht aber ursprünglich auf der Bestimmung eines zufälligen Fehlers, so dass ![]() zur Abschätzung des systematischen Fehlers verwendet werden kann.
zur Abschätzung des systematischen Fehlers verwendet werden kann.
Systematische Fehler
Die direkt gemessenen Größen ![]() seien mit den systematischen Fehlern
seien mit den systematischen Fehlern ![]() verfälscht. Gesucht ist die Größe A, die eine Funktion der N gemessenen Werte ist. Wir haben aber die verfälschte Größe A0 bestimmt. Für sie gilt, nach einer Taylor-Entwicklung
verfälscht. Gesucht ist die Größe A, die eine Funktion der N gemessenen Werte ist. Wir haben aber die verfälschte Größe A0 bestimmt. Für sie gilt, nach einer Taylor-Entwicklung
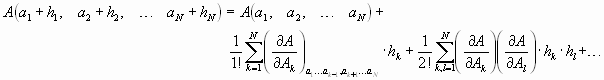
Da in aller Regel die Fehler klein gegen die gemessenen Werte sind, darf mit der linearen Näherung gerechnet werden.
Also ist das Fehlerfortpflanzungsgesetz für systematische Fehler
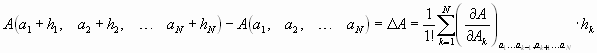
Beim Übergang zu den relativen Fehlern erhält man:
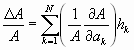
Rechenregeln
Statistische Fehler
Unabhängigkeit von der Reihenfolge der Auswertung
Wir nehmen wieder an, dass die gesuchte Größe A aus den direkt gemessenen Größen ![]() bestimmt sei. Diese sind mit zufälligen Fehlern behaftet. Wenn ak n-mal gemessen wurde, so bezeichnen wir die j-te Messung der k-ten Größe mit akj. Der Mittelwert von ak ist
bestimmt sei. Diese sind mit zufälligen Fehlern behaftet. Wenn ak n-mal gemessen wurde, so bezeichnen wir die j-te Messung der k-ten Größe mit akj. Der Mittelwert von ak ist
![]()
und die Varianz
![]()
es gibt nun zwei Wege, wie wir von den gemessenen Größen auf das Endresultat kommen können. Sind die beiden Wege äquivalent?
Wir können zuerst jede einzelne Messung mitteln, und dann in unsere Funktion für das Endresultat einsetzen.
![]()
Wir können auch jeweils die j-te Wiederholung der Messung einsetzen und dann mitteln.
![]()
Nun lässt sich der Wert von Aj durch eine Taylor-Entwicklung angeben.
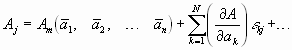
Wenn die Abweichungen von den Mittelwerten klein sind gegen die Mittelwerte, haben wir
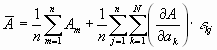
Wenn wir nun im 2. Glied die Reihenfolge der Summation vertauschen, dann finden wir
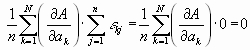
Also gilt:
![]()
Die obige Formel gilt ziemlich allgemein, z.B. auch wenn nicht alle Teilresultate gleich häufig gemessen wurden.
Gauß’sches Fehlerfortpflanzungsgesetz
Wir nehmen an, dass die Varianzen ![]() der gemittelten Messwerte ak bekannt seien. Die Varianzen sind, nach der allgemeinen Definition,
der gemittelten Messwerte ak bekannt seien. Die Varianzen sind, nach der allgemeinen Definition,
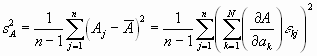
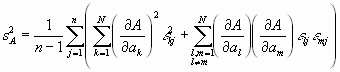
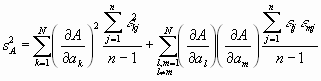
Wenn die Messungen der ak voneinander statistisch unabhängig sind, dann summieren sich alle Kreuzprodukte zu 0. Also ist das Gauß’sche Fehlerfortpflanzungsgesetz
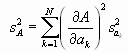
Teilen wir beide Seiten mit n, erhält man das Fehlerfortpflanzungsgesetz für die mittleren Fehler der Mittelwerte, die in der Praxis am meisten angewandte Form.
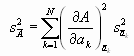
Statistische Unabhängigkeit
Wenn die Messwerte ak statistisch unabhängig sind, dann treten in 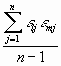 positive und negative Zeichen mit gleicher Häufigkeit auf. Wenn diese Summe null ist, nennt man die beiden Messgrössen ak und am statistisch unabhängig. Dies wird mit dem Begriff der Kovarianz beschrieben
positive und negative Zeichen mit gleicher Häufigkeit auf. Wenn diese Summe null ist, nennt man die beiden Messgrössen ak und am statistisch unabhängig. Dies wird mit dem Begriff der Kovarianz beschrieben
![]()
wobei der Operator E den Erwartungswert berechnet. Wieder gilt, dass wenn die Größen x und y voneinander statistisch unabhängig sind, dass die Produkte in der Summe für den Erwartungswert mit gleicher Häufigkeit und beide Vorzeichen annehmen.
Wenn wir eine vollständige Korrelation haben, also![]() , dann gilt
, dann gilt
![]()
Die Kovarianz geht also im Falle einer vollständigen Korrelation in die Varianz über.
|
Das Gauß’sche Fehlerfortpflanzungsgesetz darf nicht angewandt werden, wenn Korrelationen existieren (angezeigt durch die Kovarianz)
|
Angabe von zufälligen Fehlern
Da nach dem Gauß’schen Fehlerfortpflanzungsgesetz positive und negative Fehler gleich häufig vorkommen, muss der Fehler wie folgt angegeben werden:
![]()
Es gelten die folgenden Rechenregeln:
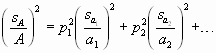
Maximaler Fehler
Will man nicht so viel rechnen, dann verwendet man die zu der Fehlerfortpflanzung bei systematischen Fehlern verwendete Funktion, bildet aber von jedem Summanden den Betrag.
Ausgleichsrechnung "Fitten"
Wenn bei einer Messung ein funktionaler Zusammenhang bestätigt werden sollte, möchte man die gemessenen Daten an theoretische oder empirische funktionale Zusammenhänge anpassen. Insbesondere wenn mehr Messdatensätze als freie Parameter existieren, muss eine Anpassung durchgeführt werden.
Graphische Verfahren
Ein graphischer Ausgleich, d.h. man legt die angepasste Kurve so über die Daten zu legen, dass die Gerade die gemessenen Daten am besten anpaßt. Dazu müssen die Daten so dargestellt werden, dass ein linearer Zusammenhang zwischen den Variablen existiert. Dies kann zum Beispiel bei einer Exponentialfunktion ![]() , wie sie bei Zerfallsprozessen auftreten kann, durch logarithmieren und Darstellen der Funktion
, wie sie bei Zerfallsprozessen auftreten kann, durch logarithmieren und Darstellen der Funktion ![]() geschehen.
geschehen.
Parktische Regeln für einen graphischen Ausgleich:
Numerische Verfahren
Wir betrachten nun zuerst den einfachen Fall einer linearen Beziehung zwischen zwei Größen. Bei einer Feder wären dies die Auslenkung z, die angewandte Kraft F und die Lage des Nullpunktes z0. Ohne Verlust der Allgemeinheit kann z0=0 gesetzt werden. Folgende Annahmen können nun gemacht werden:
Kraft F ist fehlerbehaftet
In diesem Falle können wir den Fehler für den i-ten Messpunkt wie folgt angeben:
![]()
Das Prinzip der kleinsten Fehlerquadrate verlangt nun , dass
![]()
ist. Also
![]()
Diese Gleichung kann umgeschrieben werden:
![]()
oder
![]()
Auslenkung z ist fehlerbehaftet
Wir können die Gleichung für den Zusammenhang zwischen der Auslenkung und der Kraft auch so umschreiben, dass z unsicher ist. Dann gilt
![]()
Eine kurze Rechnung zeigt, dass
![]()
Auslenkung z und Kraft fehlerbehaftet
Wenn beide Messgrössen fehlerbehaftet sind, gilt:
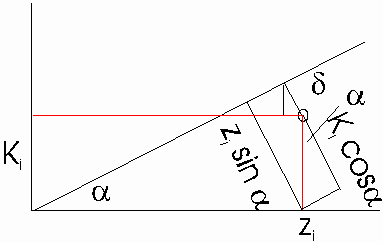
Anhand der Zeichnung findet man heraus, dass
![]()
oder
![]()
Die Summe der Abstandsquadrate muss null sein, also muss
![]()
minimal sein. Also ist
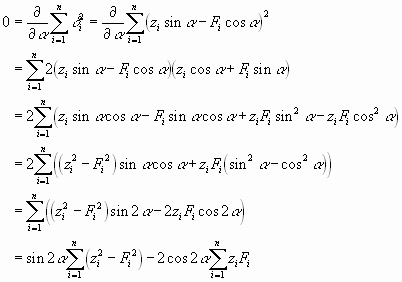
Also wird
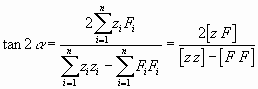
Nun ist aber
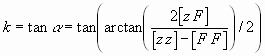
Als Beispiel ist in der folgenden Figur eine mit Zufallszahlen simulierte Rechnung zu sehen
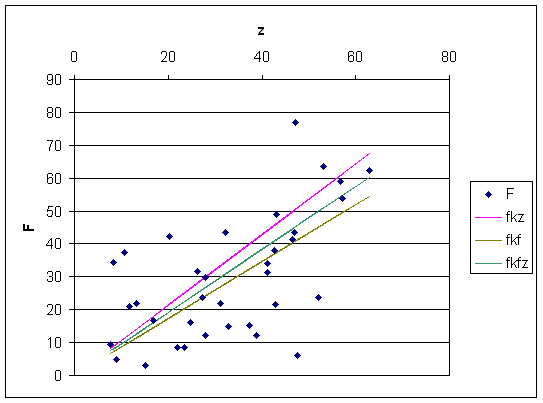
Hier bedeuten fkz die Messkurve, wenn nur z fehlerbehaftet ist, fkf, diejenige, bei der F einen Fehler hat sowie fkfz diejenige, bei der beide Größen einen Fehler haben. Bei der letzten Kurve wurde die quadratische Anpassung durchgeführt. Wichtig ist, dass dafür die Federkonstante k auf 1 umskaliert werden muss.
Ausgleichsrechnung für allgemeine Beziehungen
Wir betrachten nun die allgemeine Beziehung
![]()
bei der die unbekannten Koeffizienten Aj linear in den Gleichungen vorkommen. Wir fordern wieder, dass
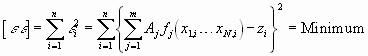
ist. Die Gleichung kann auch in Matrixschreibweise geschrieben werden:
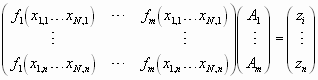
Mit der Abkürzung
![]()
wird die Gleichung
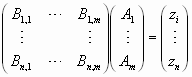
oder
![]()
Die Lösung dieses überbestimmten Gleichungssystems im Sinne der Minimierung der Fehlerquadrate ist die Lösung des m x m- Gleichungssystems
![]()
also
![]()
Bei allgemeinen funktionalen Abhängigkeiten sucht man, mit welcher Methode auch immer, Näherungswerte für die unbekannten Parameter. Ist zum Beispiel
![]()
und A0,B0,C0 Näherungswerte, so kann eine Taylor-Entwicklung durchgeführt werden.
![]()
Mit ![]() ,
, ![]() , u.s.w.,
, u.s.w., ![]() und
und ![]() ,
, ![]() u.s.w. ist die Gleichung wieder in linearisierter Form vorhanden
u.s.w. ist die Gleichung wieder in linearisierter Form vorhanden
![]()
Die oben skizzierte Methode kann zur Lösung verwendet werden. Weiter Informationen können im Buch von Zurmühl gefunden werden.
Verwenden von Excel zum Fitten
Die Anpassung von empirisch gefundenen oder theoretisch begründeten funktionalen Zusammenhängen an gemessene Daten ist nicht in jedem Falle einfach. Bei lineare Zusammenhängen funktionieren die meisten Programme sehr gut. Bei nichtlinearen Abhängigkeiten, die insbesondere über mehrere Größenordnungen betrachtet werden müssen, sind meistens Probleme zu befürchten.
Die Datenanpassung beruht auf den im obigen Kapitel angegebenen Verfahren, unter Umständen auch auf wesentlich involvierteren Verfahren wie sie in den Referenzen 1 und 2 beschrieben werden.
In dieser Vorlesung sollen Sie mit den Möglichkeiten einer Tabellenkalkulation für diese Anpassungen vertraut gemacht werden. Natürlich können auch andere Programmpakete, oft sogar besser, als Excel, das hier als Beispiel genommen wird, verwendet werden. Excel ist jedoch unschlagbar, wenn es um das Antasten an ein Anpassungsverfahren geht.
Als Beispiel verwende ich pV-Daten des Gases CO2. Diese Daten wurden mit einem, sich im Aufbau befindlichen Experiment des Grundpraktikums. Das Experiment läuft so ab, dass mit einer Mikrometerschraube das Probenvolumen, ausgehend von einem unbekannten Volumen V0 verändert wird. Eine weitere Unbekannte ist die Molzahl, da diese nur schlecht zu bestimmen ist. Wir starten mit einem leeren Bildschirm.
 In diesen Bildschirm tragen wir nun oben den Titel ein
In diesen Bildschirm tragen wir nun oben den Titel ein
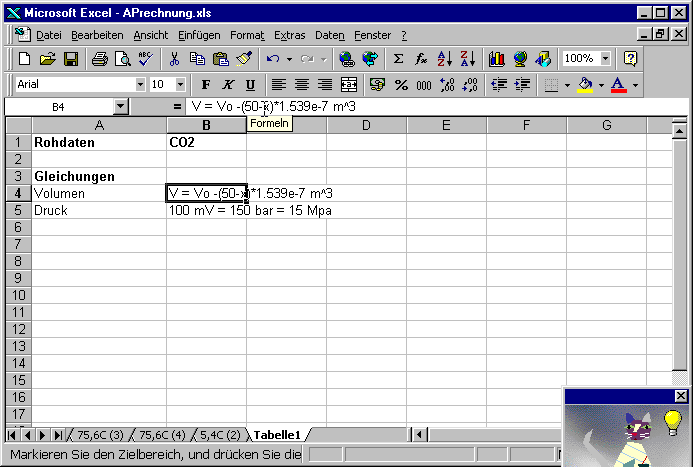 Es ist eine gute Praxis, die relevanten Gleichungen im Seitenkopf anzugeben. Hier enthalten die Zellen B4 und B5 die Umrechnungsgleichungen von den gemessenen Daten auf die physikalischen Größen.
Es ist eine gute Praxis, die relevanten Gleichungen im Seitenkopf anzugeben. Hier enthalten die Zellen B4 und B5 die Umrechnungsgleichungen von den gemessenen Daten auf die physikalischen Größen.
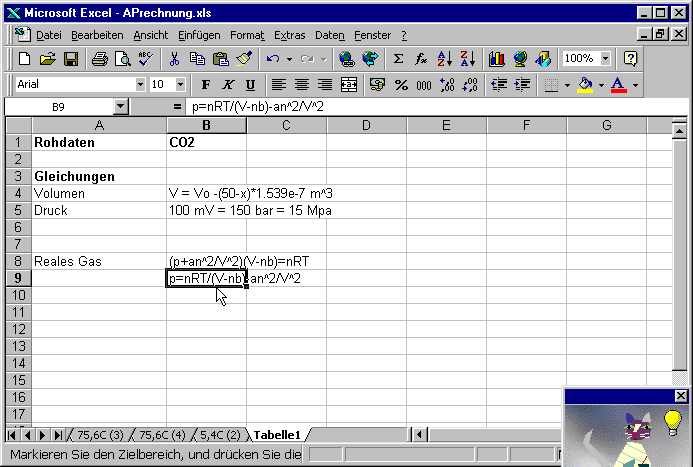 In der Zelle B8 geben wir die Gleichung des realen Gases ein, in der Zelle B9 die Auflösung nach p.
In der Zelle B8 geben wir die Gleichung des realen Gases ein, in der Zelle B9 die Auflösung nach p.
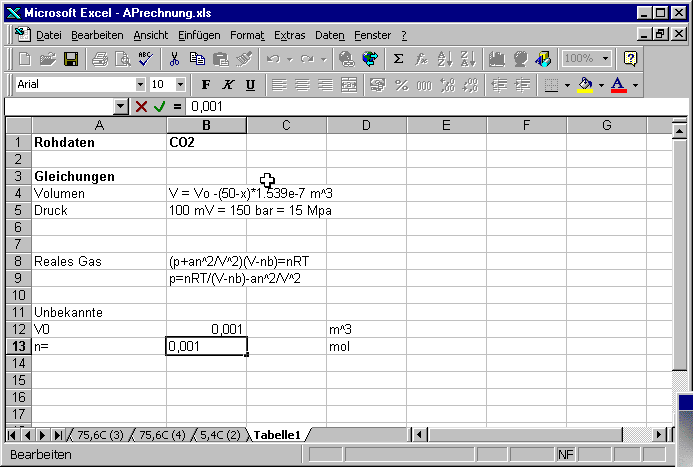 Wir geben nun in den Zellen A12 und A13 die Bezeichnungen der unbekannten Größen ein. Die Zellen B12 und B13 enthalten Anfangswerte, die Zellen C12 und C13 die physikalischen Einheiten.
Wir geben nun in den Zellen A12 und A13 die Bezeichnungen der unbekannten Größen ein. Die Zellen B12 und B13 enthalten Anfangswerte, die Zellen C12 und C13 die physikalischen Einheiten.
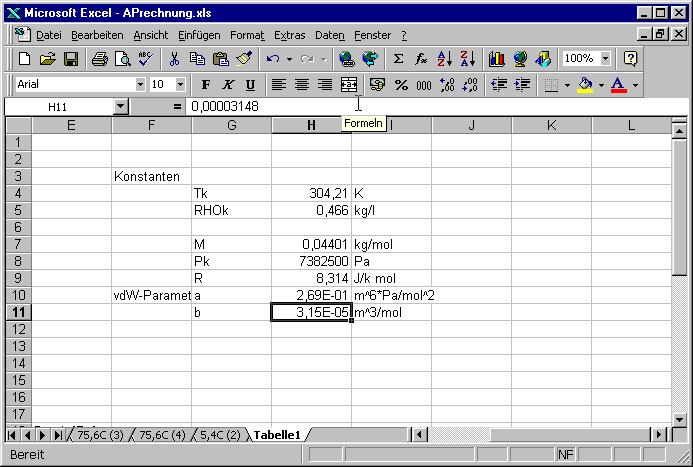 Die Zellen F3 bis I11 enthalten die Literaturwerte. Wir markieren nun den Bereich G4 bis H11.
Die Zellen F3 bis I11 enthalten die Literaturwerte. Wir markieren nun den Bereich G4 bis H11.
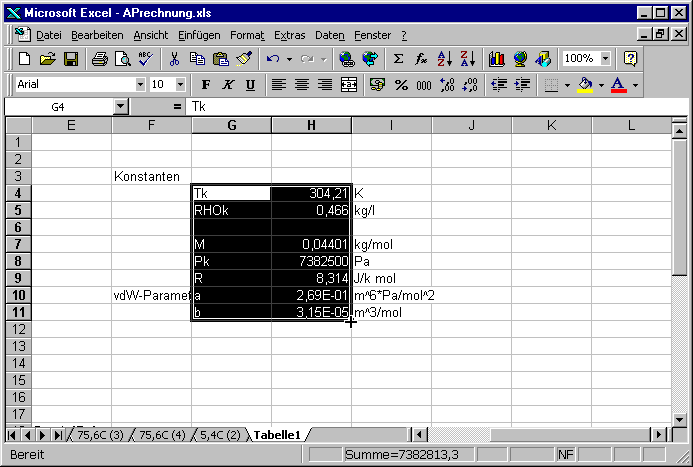 Mit dem Befehl Einfügen – Namen – Erstellen... werden die Bezeichnungen der Namen festgelegt.
Mit dem Befehl Einfügen – Namen – Erstellen... werden die Bezeichnungen der Namen festgelegt.
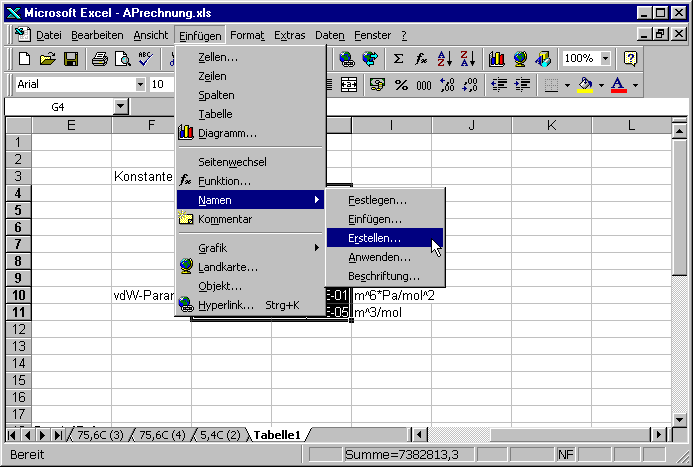 Wir wählen nun die Funktion aus linker Spalte aus.
Wir wählen nun die Funktion aus linker Spalte aus.
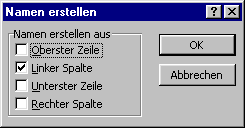 Damit werden die Namen erzeugt, die dann als absolute Referenz in Formeln verwendet werden.
Damit werden die Namen erzeugt, die dann als absolute Referenz in Formeln verwendet werden.
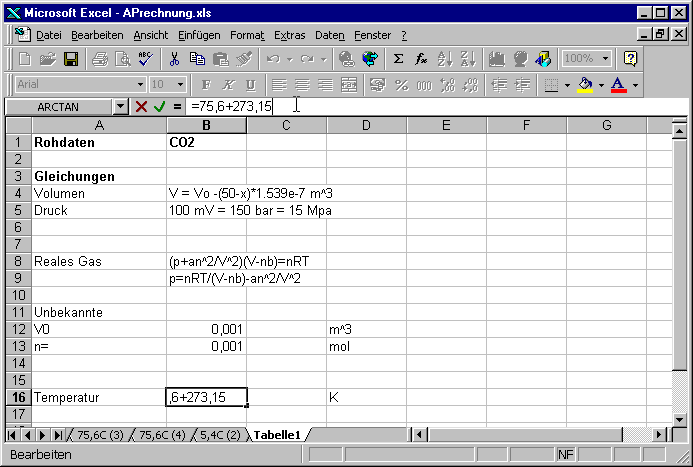 In die Zelle B16 wird die Temperatur des Gases eingegeben. Beachten Sie, dass mit absoluten Temperaturen gerechnet werden muss. Die Umrechnung kann, wie hier gezeigt, direkt in Excel durchgeführt werden.
In die Zelle B16 wird die Temperatur des Gases eingegeben. Beachten Sie, dass mit absoluten Temperaturen gerechnet werden muss. Die Umrechnung kann, wie hier gezeigt, direkt in Excel durchgeführt werden.
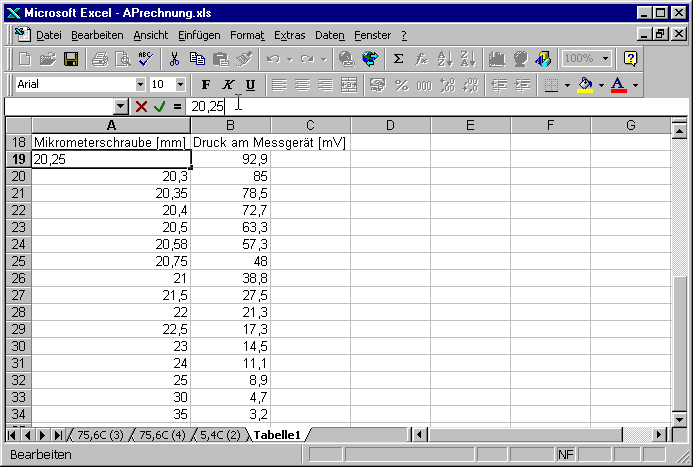 Als nächstes geben wir die Messwerte ein, für die Mikrometerschraube in mm und für den Druck in mV. Dies sind die Einheiten, die wir ablesen. Es ist eine schlechte Praxis, schon vor dem Notieren der Werte Umrechnungen durchzuführen. Wenn bei diesen Umrechnungen nämlich ein Fehler passiert, dann ist er nicht mehr auszumerzen, Wenn die Umrechnungen erst im nachhinein geschehen, haben solche Fehler, wenn sie entdeckt werden, keine Konsequenz.
Als nächstes geben wir die Messwerte ein, für die Mikrometerschraube in mm und für den Druck in mV. Dies sind die Einheiten, die wir ablesen. Es ist eine schlechte Praxis, schon vor dem Notieren der Werte Umrechnungen durchzuführen. Wenn bei diesen Umrechnungen nämlich ein Fehler passiert, dann ist er nicht mehr auszumerzen, Wenn die Umrechnungen erst im nachhinein geschehen, haben solche Fehler, wenn sie entdeckt werden, keine Konsequenz.
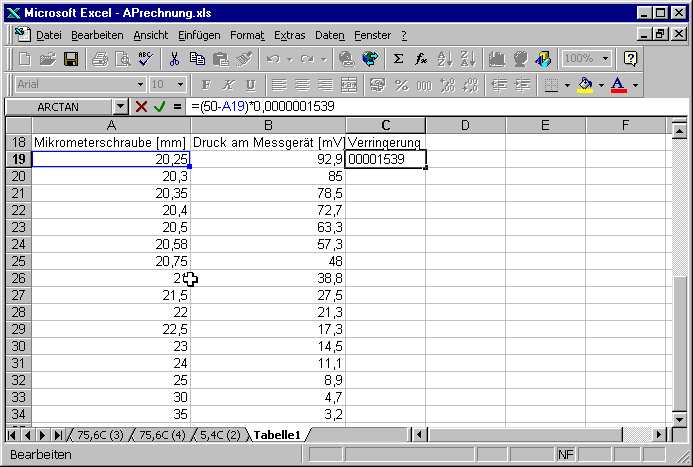 Als nächstes berechnen wir in der Spalte C die Volumenverringerung. Die Formel ist abgeleitet aus der in Zelle B4. Dabei wird zuerst das Volumen V0 außer Acht gelassen, also nur D
V = (50-x)*1.539e-7 ausgerechnet.
Als nächstes berechnen wir in der Spalte C die Volumenverringerung. Die Formel ist abgeleitet aus der in Zelle B4. Dabei wird zuerst das Volumen V0 außer Acht gelassen, also nur D
V = (50-x)*1.539e-7 ausgerechnet.
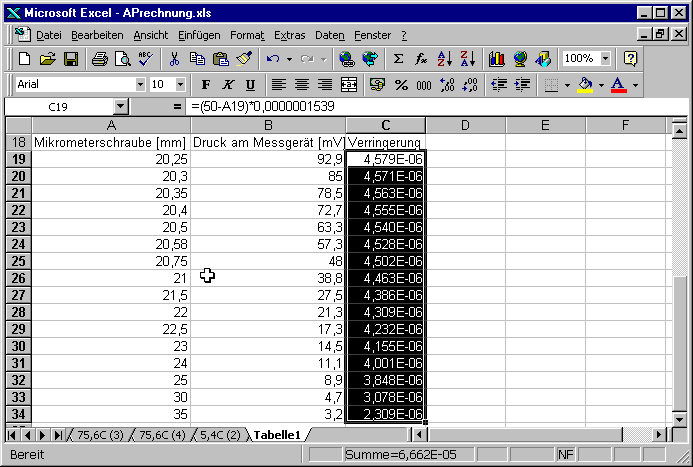 Wir markieren nun den Bereich, in den die Formel kopiert werden sollte. Mit Strg-U füllen wir den Bereich.
Wir markieren nun den Bereich, in den die Formel kopiert werden sollte. Mit Strg-U füllen wir den Bereich.
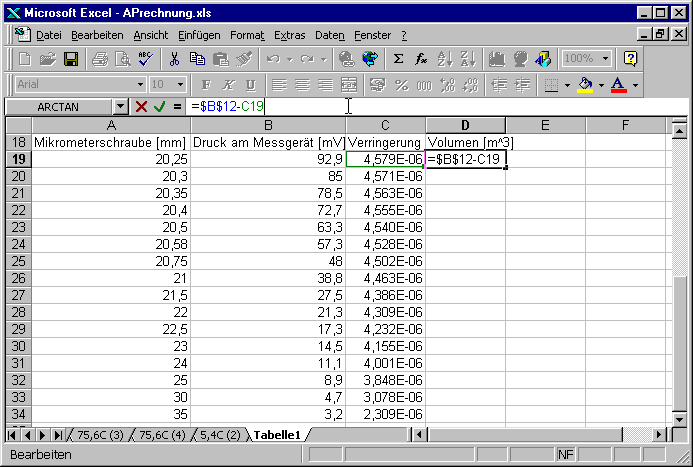 In der Spalte D wird nun das Volumen ausgerechnet. In der Formel =$B$12-C19 bedeutet die Zellenreferenz $B$12 das Volumen V0. $B bedeutet, dass beim Kopieren sich diese Spaltenreferenz nicht verändern sollte. $12 bedeutet, dass die Zeilenreferenz beim Kopieren nicht verändert werden soll. $B$12 bedeutet also eine absolute Referenz. C19 sagt, dass beim kopieren die Zellenreferenz relativ aufzufassen ist. Man kann auch Kombinationen verwenden, bei der nur die Spalten oder nur die Zeilen absolute Referenzen sind.
In der Spalte D wird nun das Volumen ausgerechnet. In der Formel =$B$12-C19 bedeutet die Zellenreferenz $B$12 das Volumen V0. $B bedeutet, dass beim Kopieren sich diese Spaltenreferenz nicht verändern sollte. $12 bedeutet, dass die Zeilenreferenz beim Kopieren nicht verändert werden soll. $B$12 bedeutet also eine absolute Referenz. C19 sagt, dass beim kopieren die Zellenreferenz relativ aufzufassen ist. Man kann auch Kombinationen verwenden, bei der nur die Spalten oder nur die Zeilen absolute Referenzen sind.
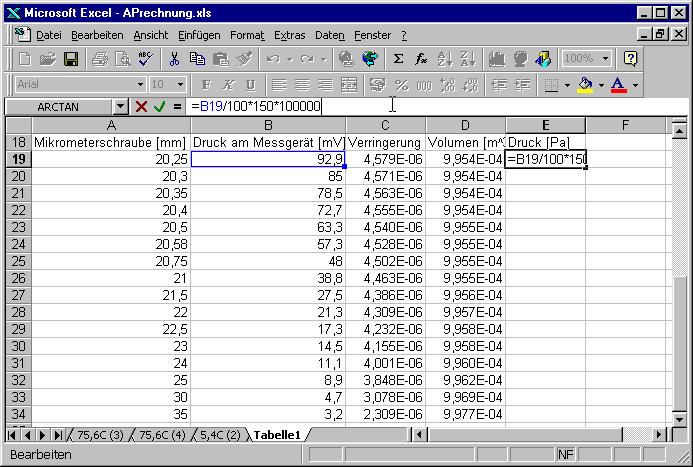 Die Spalte E enthält den in Pascal umgerechneten Druck. Dabei wird die in der Zelle B5 angegebene Umrechnung verwendet.
Die Spalte E enthält den in Pascal umgerechneten Druck. Dabei wird die in der Zelle B5 angegebene Umrechnung verwendet.
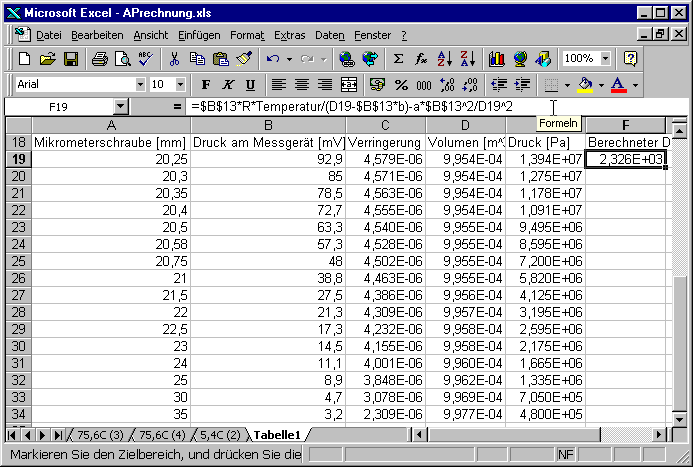 In der Spalte F wird nun der Druck mit der van der Waals Gas-Theorie ausgerechnet. $B$13 ist die zu berechnende Molzahl, D19 das Volumen, das implizit das Volumen V0 enthält.
In der Spalte F wird nun der Druck mit der van der Waals Gas-Theorie ausgerechnet. $B$13 ist die zu berechnende Molzahl, D19 das Volumen, das implizit das Volumen V0 enthält.
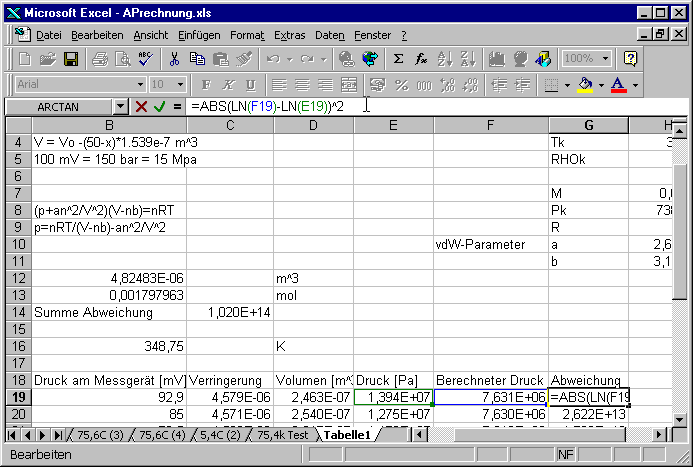
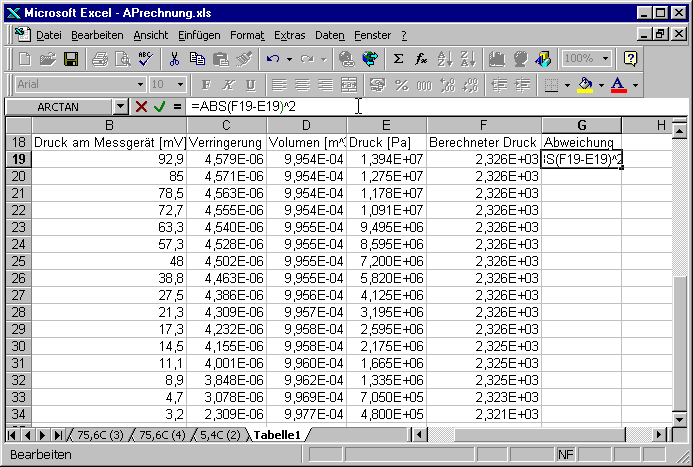 Die Spalte G enthält nun die Berechnung des Fehlers. Hier verwenden wir das Fehlerquadrat.
Die Spalte G enthält nun die Berechnung des Fehlers. Hier verwenden wir das Fehlerquadrat.
In der Zelle B14 wird nun die Summe aller Fehler eingetragen.
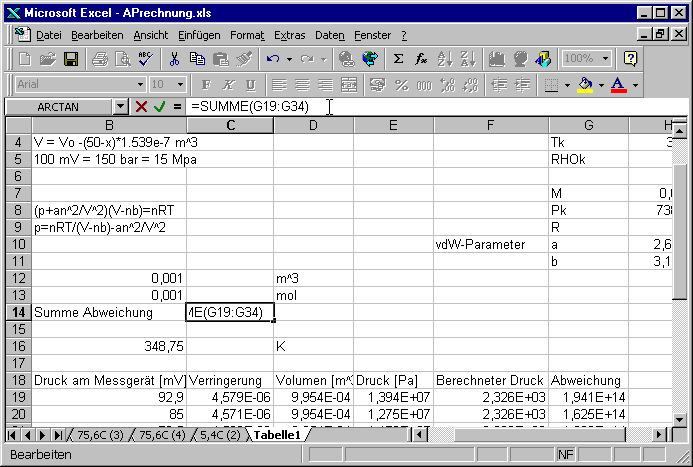 Nun können von Hand die freien Parameter verändert werden. Das erlaubt einem, den realistischen Parameterbereich abzuschätzen. Zur automatischen Abschätzung benötigen wir den Solver.
Nun können von Hand die freien Parameter verändert werden. Das erlaubt einem, den realistischen Parameterbereich abzuschätzen. Zur automatischen Abschätzung benötigen wir den Solver.
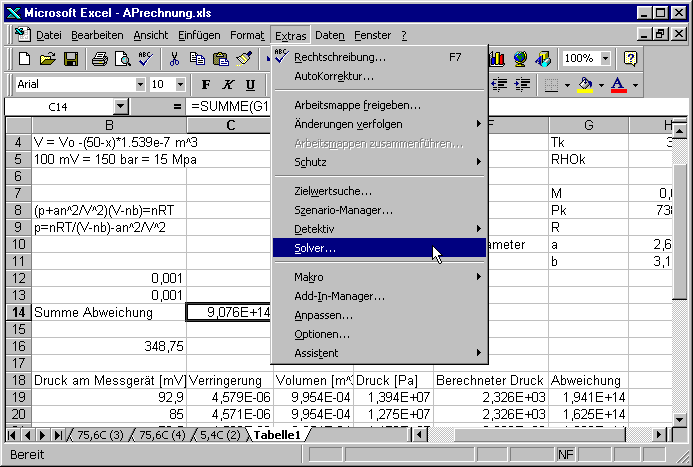 Die Einstellungen sehen so aus:
Die Einstellungen sehen so aus:
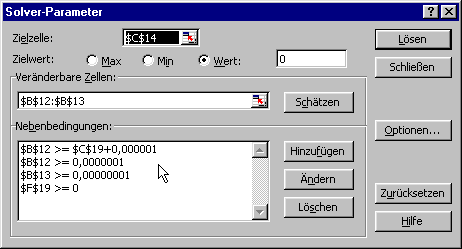 Die Zielzelle enthält die Referenz auf die Zelle, die minimiert werden soll. Der Solver funktioniert besser, wenn nicht nach einem Minimum, das ja auch lokal sein kann, sondern nach dem Zielwert 0 gesucht wird. Veränderbare Zellen sind die Molzahl und das Volumen V0. Die Nebenbedingungen verhindern, dass bei der Suche durch 0 geteilt wird. Unter den Optionen kann der Suchalgorithmus bestimmt werden.
Die Zielzelle enthält die Referenz auf die Zelle, die minimiert werden soll. Der Solver funktioniert besser, wenn nicht nach einem Minimum, das ja auch lokal sein kann, sondern nach dem Zielwert 0 gesucht wird. Veränderbare Zellen sind die Molzahl und das Volumen V0. Die Nebenbedingungen verhindern, dass bei der Suche durch 0 geteilt wird. Unter den Optionen kann der Suchalgorithmus bestimmt werden.
Nach dem Starten des Lösungsprozesses läuft die Suche. Ist sie fündig geworden, wird der folgende Dialog angezeigt.
 Wir sagen OK und unsere Datei sieht nun so aus:
Wir sagen OK und unsere Datei sieht nun so aus:
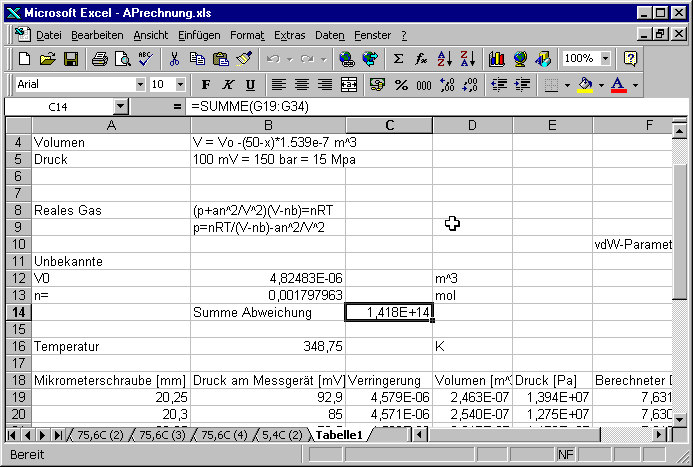 Beachten Sie die Zielzelle, und die beiden veränderbaren Zellen. Sie zeigen nun das Resultat des Fits.
Beachten Sie die Zielzelle, und die beiden veränderbaren Zellen. Sie zeigen nun das Resultat des Fits.
Es hilft oft, sich eine graphische Darstellung des Fits anzusehen. Dazu markieren wir die Spalte mit dem Volumen sowie die beiden Druckspalten.
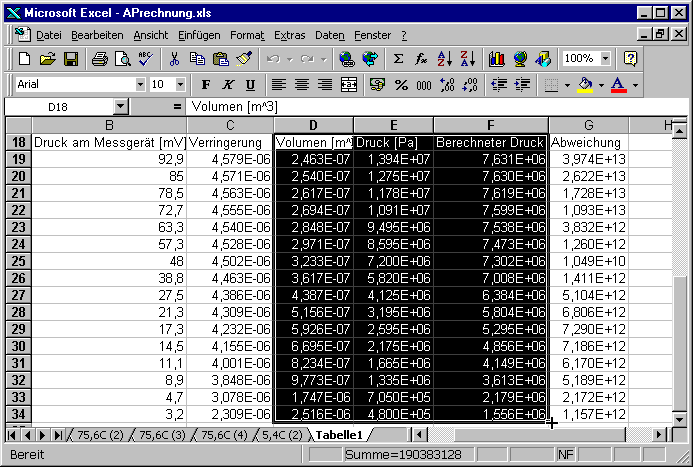 Wir drücken nun auf den Knopf für den Diagrammassistenten.
Wir drücken nun auf den Knopf für den Diagrammassistenten.
 Nun wählen wir
Nun wählen wir
 Ein Liniendiagramm ohne Datenpunkte aus und drücken Weiter.
Ein Liniendiagramm ohne Datenpunkte aus und drücken Weiter.
 Wir beschriften im nächsten Dialog das Diagramm
Wir beschriften im nächsten Dialog das Diagramm
 Und fügen es als neue Seite ein.
Und fügen es als neue Seite ein.
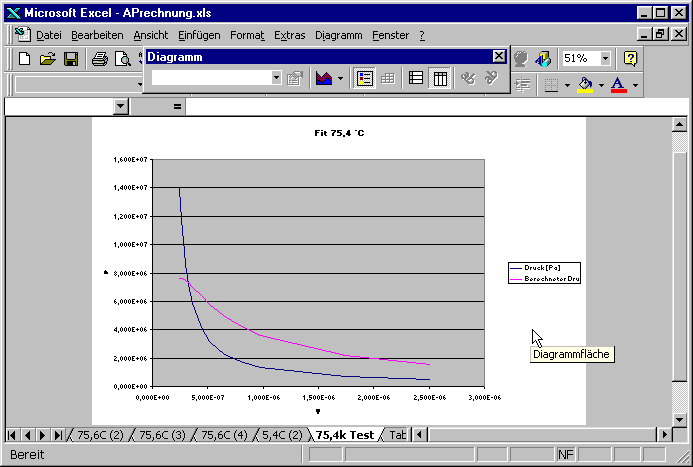 Sie sehen, dass der Fit nicht sehr gut ist.
Sie sehen, dass der Fit nicht sehr gut ist.
Ein Grund ist das 1/x-Verhalten der Kurve. Wir glätten das Ganze, indem wir logarithmieren.
 Nun fitten wir wieder und erhalten
Nun fitten wir wieder und erhalten
|
Unbekannte |
|||
|
V0 |
4,67852E-06 |
m^3 |
|
|
n= |
0,000633095 |
mol |
|
|
Summe Abweichung |
1,558E+00 |
Der dazugehörige Graph sieht folgendermaßen aus:
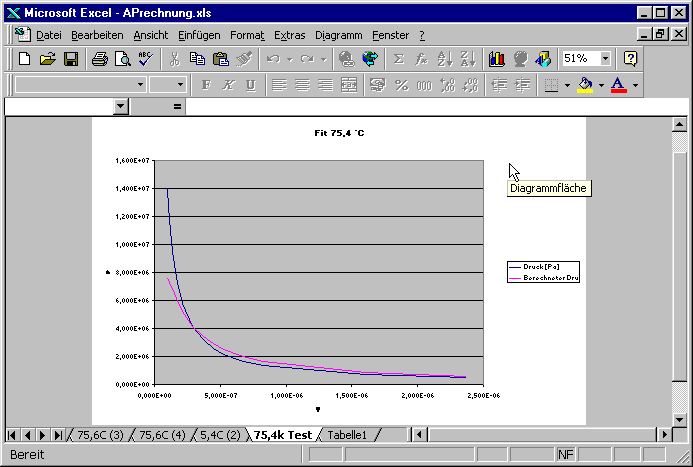 Spielen Sie mit der beiliegenden Datei Aprechnung.xls. Sie enthält die oben gezeigten Rechnungen.
Spielen Sie mit der beiliegenden Datei Aprechnung.xls. Sie enthält die oben gezeigten Rechnungen.
Literatur