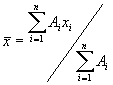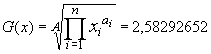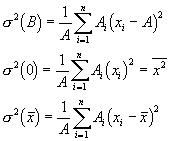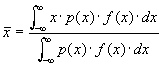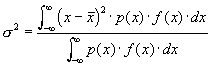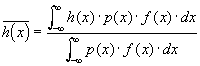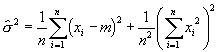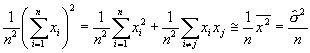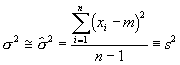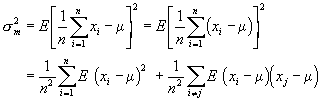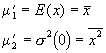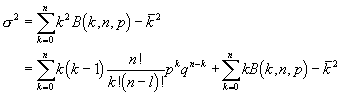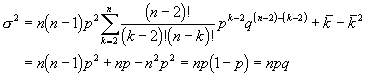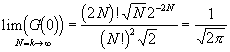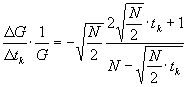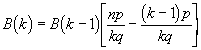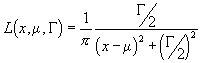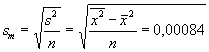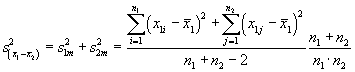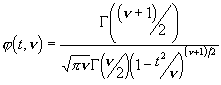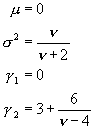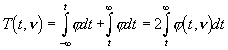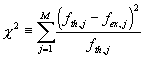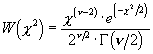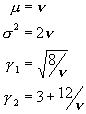|
|
|
Statistische Fehler Wenn eine Messung nur einmal durchgef³hrt wird, so kann man ³ber die Zuverlõssigkeit keine Angaben machen. Es ist deshalb unumgõnglich, Messungen zu wiederholen.
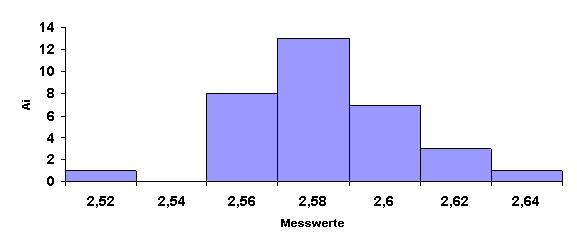
Stichproben Die erhaltenen Messresultate sind eine Stichprobe aus der Menge aller m÷glichen Messresultate. Jede Stichprobe hat eine gewisse, noch zu berechnende Wahrscheinlichkeit, dass sie die Grundgesamtheit reprõsentiert. Stichproben werden ³blicherweise als Histogramme dargestellt. Die gemessenen Daten x werden in Klassen mit (xi ¢ Dxi) < x <xi eingeteilt.
Aus diesem Histogramm kann man den Mittelwert
berechnen. Hier sind die Ai die Hõufigkeiten der in eine bestimmte Klasse fallenden Messwerte. In unserem Falle ist dies 2,583030303. Man kann diese Gleichung umschreiben, indem man die relativen Hõufigkeiten
verwendet. Der Mittelwert ist dann
Der so gefundene Mittelwert ist im allgemeinen nicht mit dem wahren Wert der Messgr÷sse identisch. Wenn wir die Klassenbreite verringern und gleichzeitig die Anzahl Messpunkte erh÷hen, so erhõlt man die differentielle Verteilungsfunktion f(x) der zugrunde liegenden Gesamtheit. Diese Funktion f(x) ist normiert, da wir die relativen Hõufigkeiten zu ihrer Ableitung verwendet hatten.
Wir m³ssen unterscheiden zwischen den aus den experimentellen Daten empirisch gefundenen Verteilungsfunktionen und den durch theoretische Modelle berechneten Verteilungen. Eine wichtige Aufgabe einer Datenanalyse kann sein, zu zeigen, dass eine empirische Verteilungsfunktion mit einer theoretisch gefundenen vertrõglich ist.
Varianzen und Standardabweichungen Eine Verteilungsfunktion ist nicht nur durch ihren Mittelwert, sondern auch durch die Lage- und Dispersionsgr÷ssen gegeben. Wir haben gesehen, dass der arithmetische Mittelwerte(oben) eine solche Gr÷sse ist. Die Lagegr÷ssen m³ssen die folgenden Postulate erf³llen:
Als Lagegr÷ssen kommen in Frage:
Der Median ist besonders dann zu verwenden, wenn die Stichprobe eine grosse Streuung aufweist. Wenn aus anderen Daten bekannt ist, dass nicht alle Messwerte die gleiche G³te haben, kann man die Ai auch als Gewicht benutzen. Hier hatten wir die Anzahl Messwerte pro Klasse als G³te des Messwertes genommen. Es ist einsichtig, dass man zusõtzlich versucht, die Breite einer Verteilung zu charakterisieren. Diese Gr÷ssen heissen Dispersionsgr÷ssen. Man verwendet:
. Wenn man die Varianz bez³glich eines andern Wertes B bildet, so gilt mit
also
Wenn wir eine kontinuierliche Verteilung haben und p(x) die Gewichtsfunktion ist, gilt:
Shepard gibt an, dass ein besserer Wert f³r die Varianz erhalten wird bei in Klassen eingeteilten Messgr÷ssen, wenn man die folgende Formel verwendet.
wobei h die Klassenbreite ist. In unserem Falle wõre
Mittlerer Fehler und Varianz
Da der Mittelwert der Grundgesamtheit, Ą, im allgemeinen nicht bekannt ist, wird die berechnete Varianz nicht die Varianz der Grundgesamtheit sein. Wir versuchen nun den besten Schõtzwert f³r die Varianz zu berechnen. Nehmen wir an, wir w³rden Ą kennen. Dann gilt
Im folgenden setzen wir alle Ai=1 und Ą=0. Dann ist A=n. Durch ausmultiplizieren erhalten wir
mit
Mit
wird
Die Gr÷sse s ist der mittlere Fehler einer Einzelmessung. Der ▄bergang von n nach n-1 ist zu Verstehen als der Verlust eines Freiheitsgrades. Da wir den Mittelwert der Grundgesamtheit Ą nicht kennen, muss die Stichprobe zur Bestimmung von m herhalten. Dies ergibt eine neue Beziehung zwischen den Datensõtzen, reduziert also die Anzahl Freiheitsgrade. Mittlerer Fehler des Mittelwertes Bei verschiedenen Stichproben schwanken der Mittelwert und die Varianz. Wenn wir f³r die Berechnung des Mittelwertes die Schreibweise
verwenden, und f³r den Erwartungswert
verwenden, dann gilt bei gleicher Grundgesamtheit f³r alle xi,
dass sie den Erwartungswert
Wenn die Messdaten statistisch unabhõngig sind, so ist der zweite Term=0 und wir erhalten
der mittlere Fehler sm des Mittelwertes ist also um den
Faktor
Daraus lernt man, dass, um ein Resultat doppelt so genau zu erhalten, viermal mehr Messungen durchgef³hrt werden m³ssen. Momente der Verteilung Das k-te Moment einer Verteilung ist definiert durch den Erwartungswert
Wenn wir B=0 setzen, so erhalten wir
Bei den h÷heren Momenten benutzt man eine Normierung, damit diese dimensionslos werden. Gebrõuchlich ausser dem Mittelwert und der Varianz sind:
. Wenn die Schiefe positiv ist, heisst das, dass gr÷ssere Abweichungen auf der positiven Seite liegen. Symmetrische Verteilungen haben die Schiefe 0. Die ▄berh÷hung (peakedness): Verteilungen Es gibt einige Modellverteilungen, die in der Physik sehr gebrõuchlich sind. Dies sind die Binominalverteilung, die bei W³rfelexperimenten oder w³rfelartigen Experimenten zugrunde liegt, die Poisson-Verteilung und, im Grenzfall sehr grosser Grundgesamtheiten, die Normalverteilung.
Binominalverteilung Die Binominalverteilung beschreibt Experimente, bei denen in jedem einzelnen Experiment mit der Wahrscheinlichkeit p ein Ereignis eintritt und mit der Wahrscheinlichkeit q=1-p ein zweites Ereignis eintritt (oder das erste nicht eintritt). Ein W³rfelspiel gen³gt, zum Beispiel, diesen Gesetzen. Die Wahrscheinlichkeit, dass k-mal das erste und n-k mal das zweite Ereignis eintritt ist
Wenn die Reihenfolge dieser Ereignisse irrelevant ist, dann hat man die Binominalverteilung
Die Verteilung ist normiert, da gilt
Der Mittelwert ist
Die Varianz schliesslich berechnet sich zu
und
Die weiteren Momente sind (ohne Rechnung)
und
F³r die Binominalverteilung existiert eine Rekursionsformel:
Zum Abschluss noch eine kurze Bemerkung: jede, auch asymmetrische Binominalverteilung geht f³r festes p bei grossen n in die Normalverteilung ³ber. Normalverteilung Die Normalverteilung kann als Grenzfall der Binominalverteilung angesehen werden, wenn die Anzahl Versuche gegen unendlich geht und p=q=0,5 ist. Die Wahrscheinlichkeit f³r das Auftreten einer Abweichung ist
wobei k negative und 2N-k positive Abweichungen auftreten. Wir k÷nnen die Binominalverteilung verwenden:
Wir berechnen den Mittelwert. Mit
Die Varianz wird dann
F³r grosse N ist es sinnvoll, die Verteilung auf die Varianz 1 zu standardisieren
Diese standardisierte Variable tk hat den
Mittelwert 0 und die Varianz 1. Verwenden nun Histogramme, und skalieren die
Achse mit
Mit der Stirlingschen Formel
wird
Mit Hilfe der Rekursionsformel kann gezeigt werden, dass
F³r p=q=1/2 wird
F³r N« ź ergibt sich
Daraus folgt
Mit einer Normierung erhõlt man die standardisierte Gaussverteilung
oder die allgemeine Gaussverteilung
Die Gaussverteilung ist symmetrisch bez³glich des Mittelwertes Ą, also sind alle ungradzahligen Momente 0. Die gradzahligen Momente haben den Wert
Damit wird zum Beispiel die ▄berh÷hung g4=3. Viele Experimente ergeben eine gaussf÷rmige Verteilung der Messwerte um einen Mittelwert. Zur Abschõtzung von Fehlergrenzen kann das Integral der Gaussverteilung, die Fehlerfunktion verwendet werden.
F³r den speziellen Wert
Poisson-Verteilung Bei radioaktiven Atomen ist die Anzahl in einer bestimmten Zeit zerfallender Kerne proportional zur Gesamtzahl der Kerne. Es gilt also
Daraus folgt das Zerfallsgesetz
Anstelle der Zerfallskonstante wird meistens die Halbwertszeit TĮ = ln 2 / l angegeben. Unter den folgenden Annahmen kann man die dazugeh÷rige Verteilungsfunktion ableiten.
Viele St÷sse ergeben nun eine Folge von Stosszeiten (k1,k2,k3...). Wir berechnen nun den Erwartungswert E(k)=Ą. Mit der Zerfallswahrscheinlichkeit p (proportional zu l und Dt) wird
Die Wahrscheinlichkeit f³r eine Zahl k von Ereignissen im Messintervall Dt kann aus der Binominalverteilung durch einen Grenz³bergang nach unendlich (n« ź , p« 0, q« 1, np=Ą=const) berechnet werden. Wir verwenden die Rekursionsformel f³r die Binominalverteilung
Daraus entsteht die Rekursionsformel f³r die Poisson-Verteilung
Mit der Normierungsbedingung
Und daraus die Poissonverteilung
Die Poissonverteilung hat die folgenden Eigenschaften (erhalten aus dem Vergleich mit der Binominalverteilung):
Die Poisson-Verteilung findet man immer dann, wenn ein sehr unwahrscheinliches Ereignis bei einer grossen Zahl Versuchen betrachtet wird. Neben Atomkernen sind auch die Ankunftszeiten von Photonen und Elektronen bei sehr geringem Fluss poissonverteilt.
Lorentz-Verteilung Die Lorentzverteilung tritt in optischen Spektren auf. Sie ist da die universelle Verteilungsfunktion. Sie wird in allgemeiner Form so geschrieben:
Die Lorentzverteilung besitzt die folgenden Eigenschaften:
Statistische Tests Die in physikalischen Experimenten erhaltenen Daten stellen Stichproben aus einer Grundgesamtheit dar. Wir m³ssen nun die folgenden Fragen l÷sen:
Ein einfacher Test kann anhand der Standardabweichungen durchgef³hrt werden. So soll untersucht werden, ob bei einer Gesamtwurfzahl von 315672 die Zahl von 106602 W³rfen der zahlen 5 oder 6 zur Annahme eines Homogenen W³rfels (p=1/3) passt. Im Versuch ist die relative Hõufigkeit 0,3377=106602/315672. Weiter ist die Standardabweichung des Mittelwertes
Man erwartet f³r einen homogenen W³rfel Ą=105224 mit
Die beobachtete Abweichung ist jedoch 1378, also 5,2 mal gr÷sser als s. Dieser einfache Test kann gut zu einer ersten Abschõtzung der G³te einer Messung dienen. Ein weiterer einfacher Test benutzt den Vergleich der h÷heren Momente. F³r diesen Dispersionsindex gilt
t-Test Der t-Test gibt eine Angabe ³ber die Konsistenz zweier Mittelwerte. Er erlaubt eine Aussage, ob eine eigene Messung mit der eines andern (aber auch eine fr³here eigene Messung) konsistent ist. Damit kann getestet werden, ob eine Apparatur sich mit der Zeit verõndert. Man k÷nnte zur Annahme gelangen, dass wenn zwei Mittelwerte Besser ist es, den erwarteten Fehler der Differenz
dabei sind F³r die t-Verteilung und den t-Test betrachtet man normalverteilte Zufallsvariablen y. Sind solche nicht vorhanden, dann muss mit Mittelwerten von Stichproben gerechnet werden. Wir berechnen den Mittelwert my aus der Stichprobe y und die Standardabweichung sy, die auf n Freiheitsgeraden beruht. Die t-Gr÷sse ist dann
Sie gehorcht der Studentschen t-Verteilungsfunktion
Diese Verteilungsfunktion besitzt die Kenngr÷ssen
F³r n▐ ź geht die Verteilung in die Normalverteilung ³ber. Die Integrale Verteilungsfunktion
ist die Wahrscheinlichkeit, dass bei Abwesenheit systematischer Fehler t-Werte auftreten, die ausserhalb des Konfidenzbereiches ▒ t liegen. Diese Funktion findet man in Tabellen. F³r sehr umfangreiche Stichproben geht die t-Verteilung in die Normalverteilung ³ber. F³r die (0,1) [Mittelwert 0, Varianz 1] verteilte Testgr÷sse bekommt man
Wenn der Test erf³llt ist, dann sind die beiden Stichproben aus der gleichen Grundgesamtheit.
F-Test Der F-Test ist ein zum t-Test analoger Test, der die Konsistenz von Varianzen pr³ft.
Die Verteilungsfunktion enthõlt die beiden Freiheitsgrade Chi-Quadrat-Test Beim c 2-Test liefert ein allgemeines Kriterium f³r die ▄bereinstimmung der Grundgesamtheit mit der Stichprobe. Der c 2-Test taugt f³r jede Verteilungsfunktion, ist also modellfrei. Das Vorgehen ist folgendermassen:
ist ein integrales Mass f³r die statistischen Abweichungen der beobachteten Hõufigkeiten. Die Verteilungsfunktion lautet:
Die kennzeichnenden Gr÷ssen sind:
Die c 2-Verteilungsfunktion ist verwandt mit der Poisson-Verteilung: sie geht f³r grosse n in die Normalverteilung ³ber. Wir rechnen nun die Wahrscheinlichkeit f³r den c 2-Wert aus der Probe aus. Der Test, ob die Stichprobe zur hypothetischen Grundgesamteit passt, gilt als bestanden, wenn die Wahrscheinlichkeit >5% ist. F³r die Anzahl Freiheitsgrade gilt:
Solche Beschrõnkungen sind die Normierung von fth und die Mittelwertbildung. F³r den c 2-Test ergibt sich demnach
Wenn ich bei einer Stichprobe mit 8 Messwerten ausrechne,
dass der Mittelwert
vollkommen unsinnig. Ist der Fehler nõmlich normalverteilt,
so erhõlt man f³r
|
|
[Einf³hrung] [Statistische Fehler] [Fehlerfortpflanzung] [Ausgleichsrechnung "Fitten"] [Fitten mit Excel]
(c) Experimentelle Physik, Universitõt Ulm Freitag,
4. Juli 2003 |